





用jTessBoxEditorFX训练字库
软件下载:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
官方字库下载:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#format-of-traineddata-files
建议:普通版本和FX版本都下载,用普通版本调整坐标,用FX版本调整汉字识别。FX版本的坐标调整不能输入数字,一旦坐标偏移太大,简直就是反人类设计。
另外,也可以直接使用普通版本,虽然在Box Editor页面里看不到汉字,但是可以用Notepad++直接打开box文件进行文字编辑。
文中用的是FX2.0beta版,有些小问题,但是不影响使用,目前正式版应该是2.2。
1、点击tools后再点击Merge TIFF,将所需要的图片集转换成tif格式,源图片集格式支持jpg和tif两种。合成的图片集命名格式为[chi_sim].[test].[exp0].tif 第一个空是字典格式,第二个字体(自定义)名字,第三个空位exp[0]。
2、生成BOX文件,D:jTessBoxEditorFX esseract-ocr esseract.exe chi_sim.test.exp0.tif chi_sim.test.exp0 -l chi_sim batch.nochop makebox
Tesseract Open Source OCR Engine v4.00.00alpha with Leptonica Page 1 Page 2 Page 3 Page 4
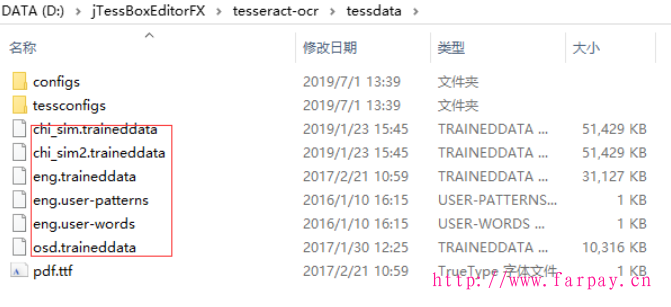
-l chi_sim参数是使用已经有的中文训练字库 这个字库是在tessdata目录里,可以自己拷贝进去
3、调整字体坐标,调整识别错误的汉字。使用open打开刚才生成的tif文件,根据刚才生成的box文件调整字库。这个步骤才是真正核心的步骤,也是最麻烦的地方。
调整坐标建议使用普通版本,FX版本无法手动调整坐标,不知道是不是故意设置还是BUG。
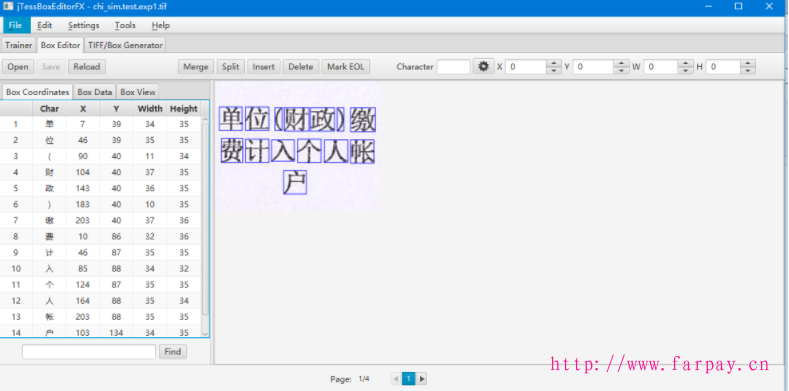
merge合并的时候有几个图片文件,这里就需要按page页分别调整。
4、调整完成box文件后,就需要生成tr文件
D:jTessBoxEditorFX esseract-ocr esseract.exe chi_sim.test.exp0.tif chi_sim.test.exp0 nobatch box.train
5、生成unicharset文件
D:jTessBoxEditorFX esseract-ocrunicharset_extractor.exe chi_sim.test.exp0.box
6、新建font_properties文件 用记事本新建一个明文font_properties.txt
内容格式为test 0 0 0 0 0,test是新建tif中间的内容(chi_sim.test.exp0.tif)。
7、在分别运行三个命令对tr特征集合进行操作
生成shape文件
D:jTessBoxEditorFX esseract-ocrshapeclustering.exe -F font_properties.txt -U unicharset chi_sim.test.exp0.tr
生成聚集字符特征文件
D:jTessBoxEditorFX esseract-ocrMftraining.exe -F font_properties.txt -U unicharset -O unicharset chi_sim.test.exp0.tr
生成字符正常化特征文件
D:jTessBoxEditorFX esseract-ocrcntraining.exe chi_sim.test.exp0.tr
8、重命名把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上test.(就是你的tif中间的名字)
9、组合文件,成功后会生成test.traineddata训练库文件。
D:jTessBoxEditorFX esseract-ocrcombine_tessdata test.(后面是有点的)
10、识别测试,把test.traineddata拷贝到D:jTessBoxEditorFX esseract-ocr essdata目录下
D:jTessBoxEditorFX esseract-ocr esseract chi_sim.test.exp0.tif output -l test
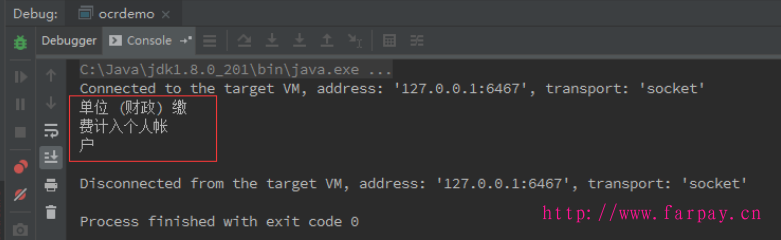
11、在代码中测试效果,可以全部识别出来,简单的代码之前发过(java 使用tess4j实现OCR的最简单样例)

12、如果需要识别的图形比较复杂,一般情况下不能对整张图片进行识别,需要把图片分块识别,用代码也好实现,关键是准备阶段划分图片区域比较费事。
public static void main(String args[]) throws Exception {
ITesseract instance = new Tesseract();
instance.setDatapath("tessdata"); //相对目录,这个时候tessdata目录和src目录平级
instance.setLanguage("test");//选择字库文件(只需要文件名,不需要后缀名)
try {
File imageFile = new File("d: emp1.jpg");
BufferedImage bufferedImage = ImageIO.read(imageFile);
Rectangle rect = new Rectangle(2581,510,249,196);//按区域读取
String result2 = instance.doOCR(bufferedImage,rect);
System.out.println(result2);
} catch (Exception e) {
System.out.println(e.toString());
}
}转载地址: https://www.cnblogs.com/asker009/p/11119005.html
版权声明
1.本站大部分下载资源收集于网络,不保证其完整性以及安全性,请下载后自行测试。
2.本站资源仅供学习和交流使用,版权归资源原作者所有,请在下载后24小时之内自觉删除。
3.若作商业用途,请购买正版,由于未及时购买和付费发生的侵权行为,与本站无关。
4.若内容涉及侵权或违法信息,请联系本站管理员进行下架处理,邮箱ganice520@163.com(本站不支持其他投诉反馈渠道,谢谢合作)
- 上一篇: WebView文件下载
- 下一篇: Windows下NDK环境的具体配置及Cygwin的安装


发表评论